


来源:优设 作者:styletin
字符集里的每一个编码对应的是一个“字”而不是“字形”,也就是说一个“字”在不同的地区或标准中可能有不同的“字形”,但字符集中只能对其分配一个编码(除非相差过大,比如简化字),要显示其不同的“字形”要通过使用为不同地区或标准设计的字体来实现。

△ 同字异形。左边是简体中文的,右边是日文
字符集是为字分配一个编码(码点),而这个字存储到文件要再通过特定编码方式(Encoding)来变成实际的二进制数据,这样做的意义在于能够使用不定长(为了节省空间)的编码。
举一个十进制的例子来说:有两个字,编码分别是 1、15 要存储的话,最简单的方式是存储为定长数据: 01、15 。之所以要定长是为了再次读取时不会发生混淆,比如如果直接不定长存储的话,读取 10 字符时,读到第一位 1 就以为读到是 1 了。1, 15 存储为 110 再读取就变成了 1, 1, 5 了。而要定长存储的话,就要浪费很多空间,所以要再经过一次编码,比如这个例子里可以用把 1 作为标志位,读到 1 就表明这是 2 位编码的字,要再度一位。这样把两个字编码为 2、15,这样就能直接存储为 215 了,这比定长的 0115 要节省空间。这个过程就是编码方式(Encoding)来决定的。实际上的 Encoding 是根据二进制来处理的,上面的例子只是便于理解。
过去的字符集往往与编码方式相对应,比如 GB2312 就只使用 EUC-CN ,这让我们可以忽略它的编码方式,或者说把编码方式看成是字符集的一部分,统称为编码标准,比如只说某个文本是用 GB2312 文本编码。而后来出现了可能会又不同的编码方式的字符集,Unicode 字符集就有 UTF-8、UTF-16 LE 、UTF-16 BE 等编码方式,这时就要区分字符集和编码方式了。用 UTF-8、UTF-16 等编码方式存储同一个字符,它们的数据可能是不同的,但是这些数据都唯一对应于 Unicode 中的一个编码(码点:codepoint)。这本来容易理解,不过 Windows 下用 Unicode 来称呼 UTF-16 LE(应该是由于 UTF-16 LE 是 Windows 的内部 Unicode 编码所以就这么称呼)这就造成了很多误解,让人以为 UTF-8 是字符集。
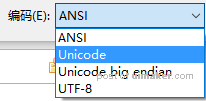
△ Windows 用 Unicode 直接代指 UTF-16 LE
代码页
代码页(codepage)是操作系统中管理各种编码标准的方法,每个代码页对应一种字符集和编码方式,比如 Unicode-UTF-8 的代码页是 65001,GBK 是的代码页是 936 。
代码页是实际编码标准到应用程序间的中间层,好处是通过改变代码页可以简单的切换系统默认支持的编码标准,而且便于更新编码标准,比如 Winodows 3.1 时代码页 936 还是对应的 GB 2312,而 winodws 95 时已经代码页 936 就更新到对应 GBK 了,这样应用程序不需要修改就能支持新的编码标准。
Windows 中把当前系统默认代码页称为 ANSI 。
GB2312、GBK 、BIG5、Shift_JIS
GB 2312 是 1980 年制定的编码标准,GBK 是对 GB 2312 的扩展(K)增加了一些字符并保持向下兼容。
BIG5 是台湾制定的编码标准,由于台湾使用繁体字,所以这是繁体地区最常用的文本编码标准。
Shift_JIS 是日本最常用的文本编码标准。
目前中国大陆的标准是国家编码标准是 GB 18030。
Unicode
上面的 GBK、Shift_JIS 等传统编码标准都只为一个地区使用所制定的,而 Unicode 是目标为所有国家、地区、语言的字编入同一个字符集,所以其被称为统一码、万国码。
Unicode 使用平面(Plane)来安排编码空间,每个平面分 为 256 行,256 列,即 65536 个字。共有 17 个平面。所以 Unicode 共可以容纳约 110 万字(1,114,112),最大的编码是 10FFFF。目前 Unicode 8.0 已经所使用了 12 万字(120,737)。Unicode 是个还在不断不断更新扩充的标准。
Unicode 的平面分为基本平面 BMP (Basic Multilingual Plane)和补充平面 (也有翻译成辅助平面)SMP(Supplementary Multilingual Plane),只有第一个平面是基本平面,也就是 Plane 0,剩下的 16 个平面都是补充平面。
如上面所说 Unicode 有多种编码(Encoding)方式,UTF-32、UTF-16 LE、UTF-16 BE、UTF-8 等,最常用的是 UTF-8 ,其基本平面的字符(主要是 ASCII 字符)只要使用 1 个字节存储,而中文通常是占 3 个字节,少数要占 4 个字节。而 UTF-16 编码第一平面的字符也要占 2 个字节,中文占 2 到 4 个字节。一般来说存储中文使用 UTF-16 要比 UTF – 8 占有更少的空间。UTF – 16 BE 和 LE 有的只是字节序的差别,BE 是大端在前,LE 是小端在前。
此外历史上还有 UCS-2、UTF7 等的编码方式,至今已经很少使用了。由于历史原因 JavaScript 内部使用的是 UCS-2 。UCS-2 可看成是 UTF-16 的字集。在没有补充平面(SMP)字符前,UTF-16与 UCS-2 所指的是同一的意思。但当引入辅助平面字符后,就称为UTF-16了。现在若有软件声称自己支持 UCS-2 编码,那其实是暗指它不能支持在 UTF-16 中超过 2 个字节的字符。对于小于0x10000的 UCS 码,UTF-16 编码就等于 UCS 码。JavaScript 在 ECMAScript 6 之前就因为这个原因无法处理大于 2 个字节字符。
BOM
BOM 是字节顺序标记(byte-order mark),通常用在 UTF-16 中标识文本的字节顺序,即区分 UTF-16 LE 和 UTF-16 BE。后来在 Windows 中被用作区分文本编码方式的标志:
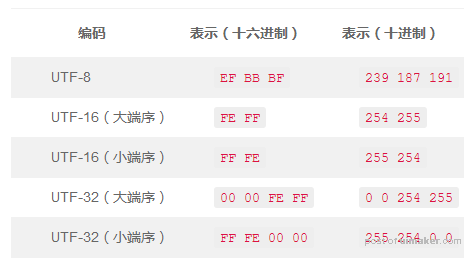
由于除了 Windows 其他系统对 BOM 的支持程度不一,所以在制作 Web 用的文本时,不应该使用 BOM。
CJK
CJK 是中日韩统一表意文字(CJK Unified Ideographs),目的是要把分别来自中文、日文、韩文、越南文、壮文中,起源相同、本义相同、形状一样或稍异的表意文字,赋予其在 UISO 10646 及 Unicode 标准中相同编码。
字体格式
TrueType
TrueType 是最常见的字体格式,后缀名为“.ttf”的字体就是 TrueType 格式。TrueType 字体的轮廓使用的是二次贝塞尔曲线,
OpenType
OpenType 可以说是 TrueType 的扩展, OpenType 有和 TrueType 一样的封装格式(SFNT),可以使用 TrueType 的二次贝塞尔曲线的字体轮廓,也可以使用对曲线表现效果更好的三次贝塞尔曲线 CFF(PostScript Type 2) 。
WOFF、EOT
WOFF 是 W3C 标准推荐的网页字体格式,其本质上是对 TrueType、OpenType 格式的压缩封装。EOT 是微软推出的网页字体格式,本质上是对 OpenType 格式精简再封装,虽然 EOT 不是 W3C 标准,但是由于 EOT 出现的很早(IE 4 就支持了),为了兼容性(尤其是对 IE),EOT 也是常见的网页字体·格式。
格式转换
由于 TrueType 是二次贝塞尔曲线,OpenType 一般是三次贝塞尔曲线,从三次转换到二次的过程不会是无损的,所以很可能产生偏差。而且很多 TrueType 字体的 UMP (元素/单位)设置的很低,所以从现状来看,TrueType 字体的质量往往要低于 OpenType 字体。
而从 TrueType 转换到 OpenType 格式是无损的,因为 OpenType 格式甚至可以不用把二次贝塞尔曲线转换成三次贝塞尔曲线,而是直接包含 TrueType 的曲线。

△ 三次曲线转二次曲线

△ UPM 值低(左)与 UPM 值高(高)
抗锯齿

字体的抗锯齿通常是用次像素(亚像素)对字体像素做成调整,让曲线在人眼中看起来更加平滑。
通常抗锯齿渲染的次像素分为两种,灰度的次像素和彩色的次像素。灰度的次像素是更为简单和基础的抗锯齿方法,而彩色的次像素是根据 LCD 显示器像素点的构成而设计的,目的是不仅仅控制图像的最小单位:像素,还要控制组成像素的 RGB 子像素,如下图显示,灰度次像素只能降低整个像素的亮度,而彩色的次像素,黄色能够关闭蓝色的子像素的显示,青色能关闭红色像素显示,这样就能控制子像素了:

微软的 ClearType 是典型的使用彩色次像素抗锯齿的技术,OS X 上也有类似的技术。彩色的次像素能够控制比灰度次像素更高实际显示精度,这在屏幕单位尺寸分辨率低的时候格外有效,而屏幕单位尺寸分辨率较高的场合,效果相对于灰度次像素优势就不大了,比如手机端,彩色次像素在手机上不仅会花更多性能和电量,在屏幕旋转时还需要重新计算,而且手机屏幕单位尺寸分辨率较高,所以目前手机上 Android 和 iOS 等系统都只是使用灰度次像素,只有曾经 Windows phone 7 里使用过 ClearType 。
彩色次像素的效果是完全依赖特定屏幕的(根据屏幕子像素排列顺序),所以在 PhotoShop 这样的绘图工具中都是使用的灰度次像素而不是彩色次像素,因为制作出的图片可能会在各种屏幕中展示,使用彩色次像素在一些屏幕中效果会很好,而另外的则会很差。所以使用彩色次像素的都在系统层,而且会根据检测连接显示器的型号或者用户设置来保障效果:

△ Windows 显示设置里的 ClearType 文本设置。实际上就是要你选择你屏幕的子像素排列顺序
Windows 、OS X 字体渲染差异
Windows 和 OS X 的字体渲染差异一直是富有争议,Windows 和 OS X 的字体渲染完全是从两种不同的偏好出发的, Windows 的字体渲染追求在屏幕上清晰的像素表现,而 OS X 追求的是尽可能再现字体本来的外观,这两者的差别在于 Windows 下显示字体很大程度依赖 hinting(微调)来进行像素对齐,力求点对点显示即使是要改变字体的外形。而 OS X 不依赖 hinting,即使字体显示到像素不是点对点而造成模糊,,也不愿意改变字体外形。

可以明显看到 Windows 下示例字体像素对齐更清晰、锐利但是代价是改变了字体笔画,字体笔画变细了,p 字字碗上提的特征也没有了。OS X 下示例字体由于没有强制对齐像素所以边缘较模糊,但是保留了字体的外形和笔画特点。
应该说 OS X 的字体渲染策略在高分辨率的屏幕下效果要比 Windows 更好,不过在较低低分辨率下, Windows 的字体渲染策略也有其优势,能够在低分辨率下提高字体的易辨识度。不过也有很多问题,比如由于过于追求像素的对齐,很可能产生破坏性的字形改变:

△ Windows 下字体渲染的问题,有的字体的 m 的像素对齐造成的字形改变过大
由于现在 Mac 都是高分屏,所以字体渲染比起大多都是低分屏的 Windows 要好的多,不过要是与高分屏的 Windows 相比,实际优势不是特别大。
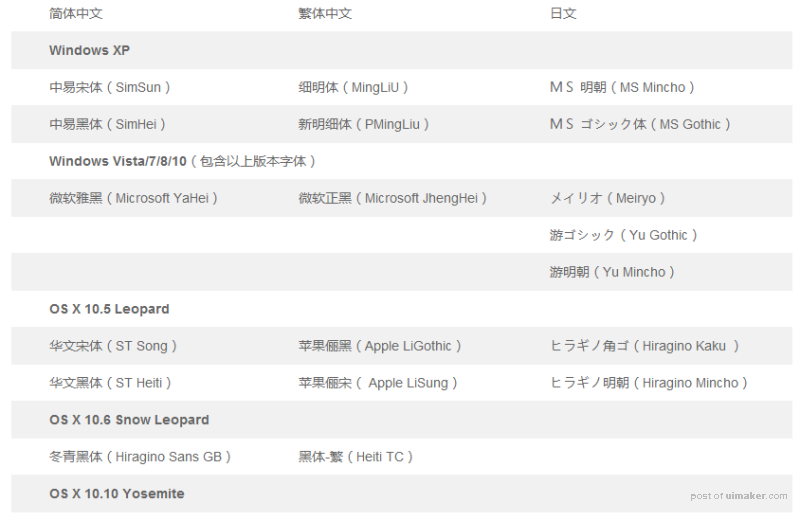
系统默认字体
桌面端
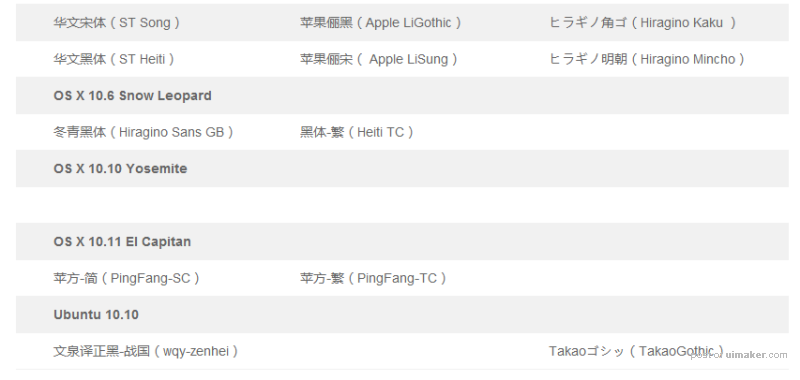
网页端





